Meta descrição: Aprenda n8n alta disponibilidade na VPS com queue mode: arquitetura com múltiplos workers, Redis e balanceador, prós, contras e boas práticas.
Rodar automações críticas no n8n é uma delícia… até o dia em que um webhook para de responder, uma execução trava ou a VPS reinicia no meio de um pico de tráfego. É aí que entra o tema deste guia: n8n alta disponibilidade na VPS com queue mode.
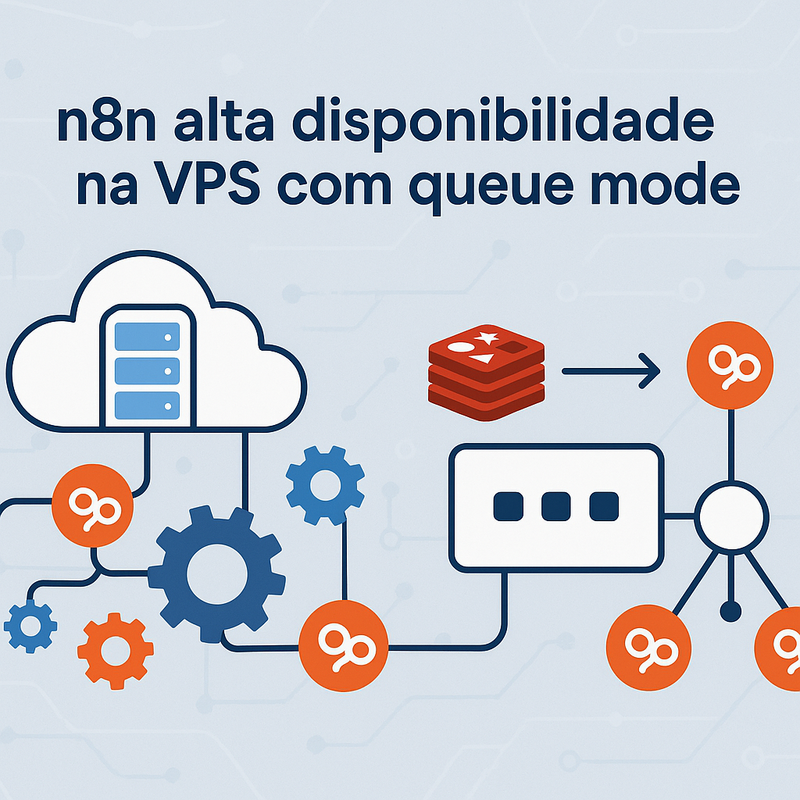
Quando você ativa o queue mode, o n8n deixa de ser “um único processo que faz tudo” e passa a separar responsabilidades: uma instância cuida da interface (editor) e do recebimento de eventos, enquanto workers processam as execuções em paralelo. No meio disso, o Redis vira a peça central para orquestrar filas e distribuir trabalho.
O objetivo deste artigo é te dar uma visão clara (e amigável para iniciantes) sobre:
- O que muda na arquitetura quando você vai para queue mode
- Como configurar n8n + Redis em uma VPS
- Como escalar com n8n múltiplos workers na VPS
- Quando faz sentido um load balancer para webhooks do n8n
- Quais são os trade-offs: custos, complexidade, pontos únicos de falha e boas práticas
Importante: “alta disponibilidade” aqui não significa “zero queda garantida”. Significa desenhar o sistema para reduzir indisponibilidades, recuperar mais rápido e aguentar mais carga com previsibilidade. Vamos por partes.
Como funciona o queue mode do n8n para alta disponibilidade
Para entender como funciona o queue mode do n8n para alta disponibilidade, vale começar pelo “modo padrão”. No modo padrão (sem fila), a mesma instância do n8n normalmente:

- Exibe o Editor/UI
- Recebe webhooks (gatilhos HTTP)
- Agenda execuções (cron)
- Executa os workflows
Isso é simples, mas cria um gargalo: se o processo ficar pesado (muitas execuções, workflows longos, consumo de CPU/memória), a UI pode ficar lenta e o recebimento de webhooks pode sofrer. Além disso, escalar costuma significar “subir uma máquina maior”, o que tem limite e sai caro.
No queue mode, o n8n separa o sistema em papéis (roles). O desenho mais comum é:
- Instância principal (web/editor): foca em UI, API interna, agendamentos e recebimento de eventos.
- Redis: gerencia a fila (mensagens/tarefas) e coordena a distribuição do trabalho.
- Workers: processos dedicados a executar workflows. Você pode ter 1, 2, 5… quantos fizer sentido.
Na prática, quando um gatilho dispara (por exemplo, um webhook recebendo um evento), a instância “web” registra/organiza a execução e coloca uma tarefa na fila. Em seguida, um worker livre puxa essa tarefa e processa a execução.
Por que isso ajuda em alta disponibilidade?
1) Isolamento de carga: se os workers estão ocupados, a UI não precisa travar junto.
2) Escalabilidade horizontal: em vez de aumentar só a VPS, você pode adicionar workers (no mesmo servidor ou em outros) para processar mais execuções.
3) Recuperação mais previsível: se um worker cai, outro pode continuar consumindo a fila (desde que Redis e banco estejam saudáveis).
Mas atenção: queue mode não transforma automaticamente sua solução em “HA de verdade”. Ele introduz novos componentes (Redis, mais processos) e, com eles, novos pontos que precisam ser bem cuidados. Além disso, alta disponibilidade real costuma envolver redundância (por exemplo, Redis em cluster/sentinels, banco com réplica etc.). Ainda assim, para muitos projetos em VPS, queue mode já dá um salto enorme em estabilidade e capacidade.
Um bom jeito de pensar é: queue mode = base para escalar e isolar, não uma “mágica” que elimina falhas.
🤖 Um caminho bem guiado para dominar n8n + Agentes de IA (sem complicar)
Se você está montando uma arquitetura mais séria (queue mode, múltiplos workers, integrações com IA, boas práticas), um atalho que ajuda muito é estudar com um roteiro pronto.
A Formação Agentes de IA (n8n) da Hora de Codar é bem alinhada com esse objetivo porque vai do básico ao avançado com projetos — e não fica só na teoria. São 11+ cursos, 221+ aulas, 20h+ e 21+ projetos, com uma pegada bem “mão na massa”. Eu gosto especialmente porque ela cobre tanto fundamentos do n8n quanto a parte de agentes (LLMs, RAG, integrações), que é onde muita automação começa a ficar realmente valiosa.
Se quiser dar uma olhada na grade e ver se faz sentido para o seu momento, aqui está o link:
https://app.horadecodar.com.br/lp/formacao-agentes-de-ia-n8n?utm_source=blog

Configurando o n8n em queue mode com Redis na VPS
Agora vamos ao que mais aparece nas buscas: como configurar n8n em queue mode com Redis — especialmente quando você está rodando tudo em uma VPS.
O checklist mental é simples: você precisa de banco de dados persistente (normalmente Postgres), Redis e pelo menos duas “peças” do n8n: uma instância web (editor) e um ou mais workers.
Componentes mínimos
Em uma VPS única (arquitetura “boa o suficiente” para começar), você pode ter:
- Postgres (para dados do n8n: credenciais, workflows, execuções, etc.)
- Redis (fila)
- n8n web (UI + API + webhooks, dependendo do seu setup)
- n8n worker (execução)
Variáveis e pontos importantes (visão conceitual)
No n8n, o queue mode é habilitado via configuração/variáveis de ambiente. O essencial é:
- Definir o modo de execução como fila
- Apontar o n8n para o Redis (host, porta, senha se houver)
- Garantir que o banco (Postgres) esteja bem configurado e persistente
Alguns cuidados que iniciantes costumam esquecer:
- Persistência: Redis pode ser usado só como fila “volátil”, mas para maior resiliência vale considerar persistência (AOF/RDB) dependendo do seu cenário. Se o Redis reinicia e perde fila, você pode perder execuções que ainda não foram consumidas.
- Rede interna: se você usa Docker Compose, mantenha Redis/Postgres em rede interna do Docker e exponha publicamente apenas o necessário (geralmente só o reverse proxy). Isso reduz risco.
- Timeouts e limites: em pico, webhooks simultâneos podem saturar conexões. É comum precisar ajustar timeouts do proxy e limites de conexões.
Um caminho prático para VPS
Se você está em uma VPS, o fluxo geralmente é:
1) Instalar o n8n (frequentemente com Docker)
2) Subir Postgres e Redis junto
3) Configurar a instância “web” para publicar o serviço (via domínio + SSL)
4) Subir um primeiro worker e validar se ele está consumindo a fila
5) Só então aumentar a quantidade de workers
O ponto-chave para o queue mode funcionar bem é o alinhamento entre web → Redis → worker. Se o Redis estiver inacessível (ou com autenticação errada), você vai ver sintomas como: webhooks recebendo mas não processando, execuções paradas na fila, ou erros de conexão.
Dica de ouro para iniciantes
Antes de pensar em múltiplos servidores, faça o básico muito bem:
- Postgres com volume persistente e backup
- Redis estável (com senha e rede restrita)
- Logs e monitoramento básico (para enxergar fila crescendo e workers morrendo)
Essa base evita a “falsa alta disponibilidade”, quando você até tem queue mode, mas qualquer reinício derruba tudo ou corrompe dados.
Se você quiser simplificar a vida no início, uma VPS que já facilite a instalação do n8n (inclusive para crescer depois para modo fila) ajuda bastante — e aqui entra a recomendação de VPS mais abaixo.
Vídeo recomendado no YouTube para complementar o estudo
Para acompanhar um passo a passo bem prático de ambiente em servidor (ótimo para quem está montando a base antes de evoluir para queue mode e múltiplos workers), recomendo este vídeo:
COMO INSTALAR n8n NA VPS EM 5 MINUTOS!
Ele ajuda a acertar o “feijão com arroz” da VPS (domínio/SSL/primeira subida), que é justamente o que evita dor de cabeça quando você começar a escalar com Redis e workers.
Assista aqui: https://www.youtube.com/embed/VCKzXFk_XjM?si=eOBTMrjZNPj3q07Z
Implementação de múltiplos workers do n8n na VPS
Depois que o queue mode está funcionando, o próximo passo natural é escalar processamento com n8n múltiplos workers na VPS. A ideia é direta: mais workers = mais execuções em paralelo (até o limite de CPU/RAM e do que seus serviços externos aguentam).
O que um worker faz (e o que ele não faz)
O worker é um processo do n8n focado em executar workflows. Em geral:
- Ele não precisa expor portas públicas
- Ele consome tarefas da fila no Redis
- Ele executa nodes, chama APIs, processa dados, grava resultados no banco
A instância web/editor continua sendo o ponto de gestão (UI) e coordenação. Isso deixa o sistema mais organizado: você escala “braço” (worker) sem bagunçar a “cabeça” (web/editor).
Como dimensionar a quantidade de workers
Não existe número mágico. Para iniciantes, uma boa regra é começar pequeno e medir:
- Comece com 1 worker e observe CPU, memória e tempo médio de execução
- Suba para 2 ou 3 workers se as execuções estiverem acumulando em fila
- Pare de aumentar quando CPU ficar constantemente alta, quando o banco virar gargalo, ou quando suas integrações externas começarem a rate-limit (muito comum em APIs)
O queue mode dá paralelismo, mas paralelismo demais pode piorar a confiabilidade se:
- Você bater limites de API (429)
- O Postgres sofrer com muitas escritas/leitura simultâneas
- A VPS começar a usar swap e ficar lenta
Um exemplo realista de cenário
Imagine que você tem:
- Webhooks de e-commerce chegando em picos (promoções)
- Workflows que fazem enriquecimento de dados e enviam mensagens
Com 1 worker, os webhooks chegam, mas a fila cresce e o tempo de processamento aumenta. Ao subir para 3 workers, você reduz o tempo médio e absorve pico melhor.
Agora, se você subir para 10 workers numa VPS pequena, pode acontecer o oposto: tudo disputa CPU/RAM, o banco fica sobrecarregado e as execuções começam a falhar por timeout.
Boas práticas rápidas
- Separe a preocupação: web estável + workers escaláveis.
- Prefira aumentar workers aos poucos, observando métricas.
- Defina limites de concorrência quando necessário (principalmente em workflows que chamam APIs sensíveis).
Esse é o ponto em que o queue mode brilha: ele te dá uma alavanca simples (quantidade de workers) para lidar com crescimento sem reinventar toda a infraestrutura.
Load balancer para webhooks do n8n: quando é necessário e como implementar
A dúvida clássica: load balancer para webhooks do n8n é obrigatório para alta disponibilidade? Nem sempre.
Em muitos projetos, você roda uma instância web única que recebe webhooks, e escala só os workers. Isso já resolve grande parte dos problemas, porque quem “pesa” geralmente é a execução — não o recebimento do webhook.
Quando o load balancer passa a fazer sentido
Você começa a considerar balanceamento quando:
- O volume de webhooks é tão alto que uma única instância web vira gargalo
- Você quer reduzir indisponibilidade caso a instância web caia (redundância)
- Você precisa de manutenção/atualizações sem derrubar o recebimento de webhooks (estratégia rolling)
Se seu n8n for parte crítica de um produto (SaaS, plataforma, automações de venda com alta dependência), um balanceador pode ser o passo natural.
O que muda na arquitetura
Com load balancer, você terá pelo menos duas instâncias web atrás de um ponto de entrada único (domínio):
- Balanceador (Nginx/Traefik/HAProxy ou um LB gerenciado)
- Web 1 e Web 2 (mesma configuração, apontando para o mesmo Postgres e Redis)
- Workers (um ou vários)
Atenção: para webhooks, você precisa consistência. Em geral, como as instâncias web compartilham banco e Redis, elas conseguem coordenar o que precisa ser executado. Mas você deve:
- Garantir que todas as instâncias tenham a mesma configuração de domínio/URL pública
- Cuidar para que o reverse proxy repasse corretamente headers (especialmente
X-Forwarded-Protoe host) - Configurar timeouts para webhooks que demoram (quando o webhook não é “fire-and-forget”)
Como implementar (alto nível)
Sem entrar em detalhes de comandos, o desenho típico é:
- Um reverse proxy como Nginx/Traefik na frente com SSL
- Regras de balanceamento para encaminhar
/e endpoints de webhook para as instâncias web - Health checks para tirar do pool uma instância web que não está respondendo
Se você está começando, a dica é: só coloque load balancer quando tiver um motivo real. Ele adiciona complexidade, e muitas vezes o “gargalo” está nos workflows (ou nos serviços externos), não no endpoint HTTP.
Em resumo: primeiro queue mode + workers. Depois, se a camada web virar ponto único de falha que te incomoda de verdade, aí sim você sobe o nível com balanceamento.
💻 VPS para n8n em produção: por que eu consideraria a Hostinger
Para rodar n8n com mais tranquilidade (principalmente pensando em n8n alta disponibilidade na VPS com queue mode), a VPS faz diferença: CPU/RAM estáveis, armazenamento rápido e possibilidade de escalar quando os workers aumentarem.
Uma opção que costuma facilitar bastante é a VPS da Hostinger, porque ela já oferece o n8n pré-instalado, dá para começar simples e ir aumentando recursos conforme o projeto cresce. Além disso, eles indicam 99,9% de uptime, têm 30 dias de garantia de reembolso e planos que vão de algo mais enxuto até bem parrudo (KVM 1 a KVM 8, com NVMe).
Se você quiser ver os planos por lá, use este link de indicação e o cupom:
- Link: https://www.hostinger.com.br/horadecodar
- Cupom: HORADECODAR
Isso ajuda bastante quando você está saindo do “n8n em uma instância só” e começando a brincar com Redis + workers, porque você consegue evoluir o servidor sem reinventar tudo.

Principais trade-offs e boas práticas na arquitetura de alta disponibilidade
Falar de n8n alta disponibilidade na VPS com queue mode sem falar de trade-offs seria te enganar. O queue mode resolve muitos problemas, mas cria outros desafios. A boa notícia é que, sabendo disso desde o início, você evita 90% das dores.
Trade-offs mais comuns
1) Mais componentes, mais pontos de atenção
Antes era “só n8n”. Agora você tem Redis, múltiplos processos, possivelmente mais logs para acompanhar.
2) Redis e banco viram peças críticas
Mesmo com vários workers, se o Postgres cair, nada funciona. Se o Redis cair, a fila para. Alta disponibilidade “de verdade” passa por pensar na resiliência desses componentes também.
3) Observabilidade vira necessidade, não luxo
Com múltiplos workers, quando algo falha você precisa saber: foi o worker? foi o Redis? foi rate-limit de API? Sem logs e métricas, você fica no escuro.
4) Concorrência pode piorar integrações
Quando você aumenta workers, você aumenta chamadas paralelas em APIs externas. Muitas APIs bloqueiam, limitam, ou cobram por volume. Um sistema “mais rápido” pode ficar “mais instável”.
Boas práticas que valem ouro
Aqui está um conjunto pequeno (mas muito efetivo) de hábitos:
- Backups regulares do Postgres e testes de restore (backup que nunca foi restaurado é só um “talvez”).
- Separar responsabilidades: web estável, workers escaláveis.
- Atualizações com cuidado: versionar seu compose/infra e evitar atualizar no meio de um pico.
- Limitar concorrência quando necessário: especialmente em workflows que batem em APIs com limites.
Alta disponibilidade “pé no chão” em VPS
Muita gente busca HA, mas ainda está em uma VPS única. Dá para melhorar muito, desde que você aceite a realidade:
- Se a VPS cair, tudo cai.
- Queue mode melhora performance e resiliência dentro do servidor, mas não substitui redundância de infraestrutura.
Por isso, a abordagem recomendada é evolutiva:
- Comece com queue mode + 1–3 workers na mesma VPS
- Depois, se o projeto crescer, você distribui: Redis/banco em instâncias melhores e workers em múltiplos servidores
- Por fim, se fizer sentido, adiciona load balancer para eliminar o ponto único na camada web
Com esse caminho, você ganha estabilidade sem “pular etapas” e sem gastar além do necessário.
Como funciona a arquitetura de alta disponibilidade do n8n em uma VPS usando o queue mode?
No modo queue, o n8n utiliza um sistema de enfileiramento (geralmente Redis) para distribuir tarefas entre múltiplos workers, proporcionando escalabilidade e resiliência. Cada worker pode processar fluxos de trabalho independentemente, enquanto um balanceador de carga distribui as requisições de maneira eficiente, aumentando a disponibilidade da aplicação e reduzindo pontos únicos de falha.
Quais são os principais benefícios de operar o n8n em modo queue com múltiplos workers numa VPS?
Os principais benefícios incluem maior tolerância a falhas, escalabilidade horizontal fácil (basta adicionar mais workers), melhor aproveitamento dos recursos da VPS e capacidade de processar múltiplos fluxos de trabalho simultaneamente. Isso resulta em maior performance e disponibilidade para automações críticas.
Quais os principais trade-offs ao adotar n8n em alta disponibilidade na VPS com queue mode?
Os principais trade-offs são o aumento da complexidade da arquitetura (incluindo a configuração e manutenção do Redis e do balanceador), maior uso de recursos computacionais e possíveis desafios no monitoramento. Além disso, em caso de má configuração, podem surgir problemas como processamento duplicado ou perda de jobs, exigindo atenção especial às boas práticas de implantação.
Conclusão
Montar n8n alta disponibilidade na VPS com queue mode é, na prática, uma mudança de mentalidade: você sai do “um processo faz tudo” e passa para uma arquitetura com papéis claros — web/editor recebendo eventos e coordenando, Redis distribuindo tarefas e workers executando em paralelo.
Para a maioria dos projetos, só essa separação já traz ganhos enormes de estabilidade e escala. E, conforme a demanda cresce, você pode evoluir de forma progressiva: primeiro como configurar n8n em queue mode com Redis, depois aumentar n8n múltiplos workers na VPS, e só então considerar um load balancer para webhooks do n8n quando a camada web virar gargalo ou ponto único crítico.
No fim, os trade-offs são previsíveis: mais componentes para operar, mais necessidade de monitoramento e mais atenção a gargalos como banco de dados e limites de API. Seguindo boas práticas (persistência, backups, observabilidade e crescimento gradual), dá para ter um ambiente bem confiável sem complicar além da conta.
Se você está começando, foque em uma base sólida na VPS, valide queue mode com um worker, e escale com calma — é assim que a arquitetura fica sustentável.